
Instacart Recommendation Engine
Data Science Project
Instacart is an online grocery / product delivery service. Users select a store, a pickup time, and the items they want to order. Those items are picked up from the store and delivered to the user in a set amount of time by an Instacart shopper. Instacart replaces the in store shopping experience. For users that like the novelty of walking through the aisles to find new items to try, some of the user experience may be lost in switching over to online shopping. Building in an item recommendation engine may bring back some of the novelty lost in translation to an app format.
View Project Code Here
Defining the Project
Research Question
How do we account for the novelty item discovery of in person shopping?
Hypothesis
Building a recommendation engine will introduce that novelty back in to online shopping by giving users new products to buy based on their purchase history
Assumptions
Recommendation engines will work best with regular users of Instacart
Metrics of Succes
Make a recommendation engine that returns five reccomendations to a use
Exploratory Data Analysis (EDA)
Does Instacart Have Repeat Users?
Using the data set we can see how many repeat customers Instacart has. In this data set there are 20,6209 unique users. The highest number of repeat orders is 100 and the lowest is 4 repeat orders.
Using a box plot we can see the average user seems to have placed between 3 and 21 orders but there is also a large user base that places more frequent orders.


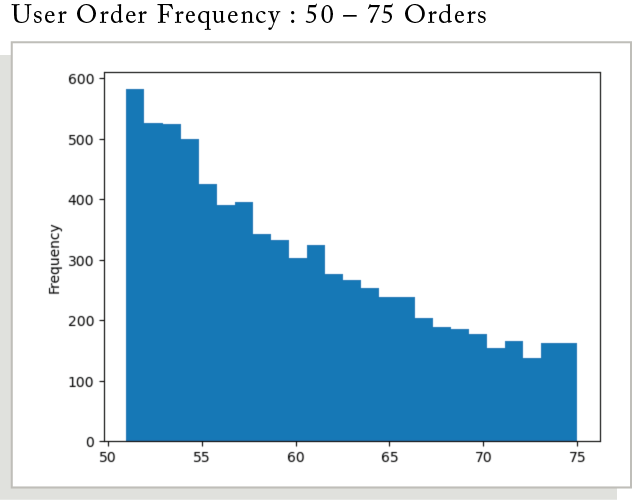
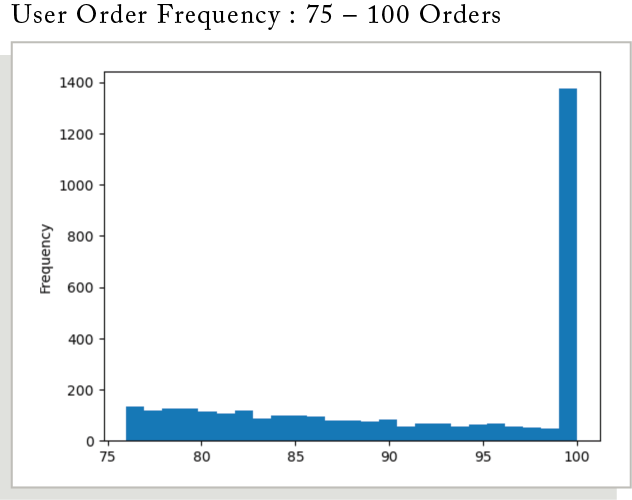
How is Order Frequency Distributed?
Breaking these in to quarters and displaying the data as a box plot helps manage and visualize the user order frequency distribution more effectively. The data distribution follows a similar decremental shape in user groups 0 – 75. However, there is a group of users that have ordered over 100 times which changes the distribution in the last quarter.
Instacart has a large user base that might order a few times for the novelty, but when they get a loyal user they are very loyal. Building in a product recommendation engine may help keep the app novel for new users.


Creating the Data Frame
Instacart data is split across 5 files. This makes it difficult to read – for example in the ordered products file, we know the number assigned to the product a user ordered but we wouldn't be able to tell what the name of that product is.
Combining the files and select the data columns relevant to creating a product recommendation engine will make it more human readable.

Final Data Frame
user_id : Who is the user? In this case we are looking at the items user 1 had bought
product_id : What is the ID number assigned to the product they’re ordering?
user_count : Across all of this user’s Instacart orders, how many times has this user ordered this product?
product_name : What is the name of the product they’re ordering?
overall_popularity : How popular is the product across Instacarts user base? ex: Soda ranks 35791

Setting Up Natural Language Processing
Natural Language Processing (NLP):
Natural Language Processing (NLP) is a set of techniques that help turn human languages in to something that is digestible and usable for a computer.
Term Frequency–Inverse Document Frequency (TF-IDF):
An NLP technique that splits words in to tokens and counts how many times they appear in a document. It then measures how important the word is to the document. It’s often used in user modeling
Using TF-IDF to Build User Shopping Profiles
We’ll use TF-IDF to understand the importance of different food items in a user’s document (order history). The more they’ve purchased an item, the more important the item is going to be within their order history. This becomes their shopping profile that we can make recommendations off of.
User 1 TF-IDF Shopping Profile

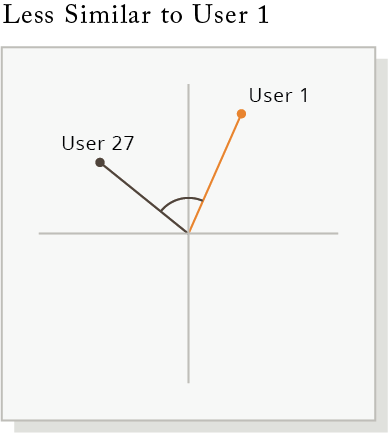
Using Cosine Similarity to Build a Recommendation Engine
Cosine Similarity
Cosine similarity lets us find the most similar user profiles by plotting them and measuring the cosine angle. The smaller the angle between two user shopping profiles, the closer their profiles are.
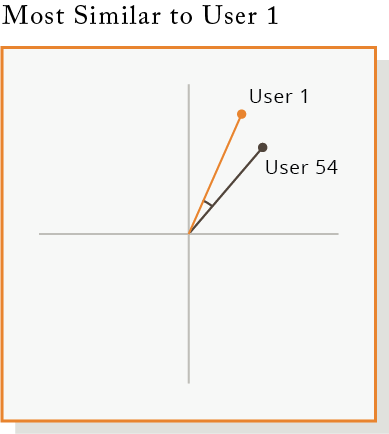
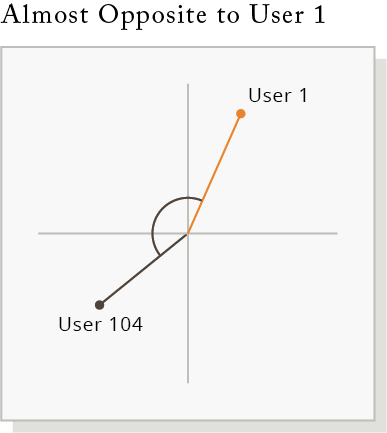
Recommending New Products From User 1’s Closest Profile
The recommendation engine is built by searching for the users closest profile – this means the user who has the most similar purchase history. The recommendation engine returns items from that closest user profile that our user has not purchased.
The hypothesis is that our user might be interested in those items because their closest user profile buys them.

Final Results & Next Steps
The recommendation engine was able to return 5 products based on a user profile. However, for it to be as effective as possible, some additional improvements should be made before implementing it in to Instacart.

The model only uses part of the full data set : due to the size of the data set the model only accounts for part of the data, running it with the full data set may improve the accuracy of it’s recommendations as there will be more user profiles to pull from.
The model does not currently account for items in the users cart : To increase the novelty of the recommendations, the model could base it’s recommendations off of users with similar carts.
It does not account for time : The model should account for changes in behavior in user shopping patterns
Some of the model’s recommendations are repetitive : The model will return items similar to what the user is already buying. For example, If they frequently buy Greek yogurt it will recommend other kinds of Greek yogurt. Filtering out product similarity would cut out repetitive recommendations.